Building Adaptive Coverage Systems for API Testing
How model orchestration, fine-tuned QA judgment, correction data, and execution feedback improve generated test quality.
Executive Summary
AI has made test generation faster, but faster generation has not solved coverage quality. Teams can produce more tests than ever and still miss the cases that matter: important edge cases, cross-field behavior, weak assertions, and suites that fall out of date as systems change.
The underlying shift is from static test suites to adaptive coverage systems. An adaptive coverage system ingests product context, plans coverage, generates executable tests, validates them through execution, learns from corrections, and updates suites as the software changes. The hard part is not generating valid tests. It is teaching the system what a QA engineer considers useful, relevant, non-redundant, and appropriately scoped.
KushoAI's architecture is one instance of that pattern. It separates QA judgment from execution mechanics. Fine-tuned models decide test and assertion intent. Frontier models handle payloads, code, framework-specific output, and execution support. Execution feedback and human corrections improve the system over time.
As one public evaluation anchor, APIEval-20 shows that the gap in AI-generated API tests appears most clearly on complex bugs involving relationships between fields, not on simple schema-level mutations. That finding frames the rest of this paper. The difference between a fast test generator and a useful one is judgment about what to test and what to assert, and the architecture described here is built to encode that judgment and validate it.
From Static Test Suites to Adaptive Coverage Systems
Traditional test automation assumes that humans define coverage and tools execute it. AI-native testing changes that assumption. The system now helps decide what coverage should exist, validates whether generated tests are useful, and maintains suites as software changes.
Static suites degrade for reasons that have little to do with how carefully they were written:
- APIs change, and endpoints gain or lose fields.
- Workflows evolve, and new dependencies appear.
- Authentication and authorization behavior shifts.
- Schemas drift away from the tests written against them.
- Edge cases missed at authoring time are never added.
- Tests go stale and stop reflecting current behavior.
- Teams patch the suites they have instead of expanding coverage.
The result is familiar: coverage that looks adequate on paper and erodes in practice. An adaptive coverage system treats coverage as something to plan, validate, and maintain continuously rather than author once.
Why Faster Test Generation Is Not Enough
Generating tests quickly is now easy. Generating a good test suite is not. When general-purpose models were used across the full pipeline, six failure modes appeared in production.
Over-generation. The model would produce 20 to 30 cases where 8 would have been sufficient. Many were plausible but not meaningfully distinct, and the excess made suites harder to review and trust.
Under-generation. In other cases the model missed obvious scenarios: omitted required fields, invalid enum values, boundary values, malformed formats, missing authentication cases, expected error responses.
Redundancy. The model generated several tests that checked the same behavior through slightly different wording or payloads, treating "invalid value," "incorrect value," and "unsupported value" as three cases when they mapped to one check.
Inconsistency. Two structurally similar endpoints could receive very different treatment, one balanced across positive, negative, and boundary coverage, the other sparse or bloated.
Weak assertions. Generated tests often check that a response exists or matches a broad schema but miss the behavior that actually matters.
Poor relationship testing. Many generated tests mutate fields independently and miss failures that appear when individually valid fields combine into an invalid state.
These are not failures of syntax or API knowledge. They are failures of coverage judgment. A model can generate valid tests and still produce a weak test suite.
API Testing as a Judgment Problem
The pattern across those failure modes points to a single cause. The models already knew what APIs were, what HTTP methods and request bodies were, and what schema validation meant. What they lacked was the judgment to decide how much testing is appropriate, which scenarios carry the most risk, which cases are redundant, and how to stay consistent across similar endpoints.
API test generation is therefore a calibration problem before it is a knowledge problem. The knowledge is broadly shared across current models. The judgment about what deserves to be tested, and how thoroughly, is the part that separates a fast generator from a useful one. The rest of this paper is about how to encode that judgment and how to validate it.
Why Prompting Helps but Plateaus
Before fine-tuning, the team worked the problem through prompting: structured prompts, multi-step prompting, context injection, explicit output schemas, few-shot examples, and detailed instructions about redundancy and coverage. Prompting helped. It improved formatting, structure, and breadth of coverage. Few-shot examples produced the largest single improvement, pulling outputs closer to what a reviewer would keep.
That result was the signal. If examples in the prompt improve behavior, the missing ingredient is broader exposure to examples of preferred QA decisions, not more general capability. Fine-tuning is few-shot prompting at a scale that exceeds the context window. Instead of fitting a handful of corrected examples into every prompt, the preferred decisions become part of the model's operating pattern.
But prompting plateaus. It mostly increases field-level exhaustiveness, more missing-field, wrong-type, and boundary tests, which are useful but remain independent mutations. It does not reliably produce reasoning about field relationships, business states, and workflow behavior. The same pattern appears in benchmark results: simple schema-level tests are easier to generate, while complex bugs involving cross-field relationships remain harder. Prompting is necessary, and on its own it is not enough.
RAG and Fine-Tuning Have Different Jobs
A reasonable question is whether retrieval-augmented generation solves this. RAG supplies context. Fine-tuning calibrates behavior. They do different jobs, and a mature system uses both.
RAG is the right tool when the system needs information it does not have:
- Internal documentation
- Product behavior
- Customer-specific policies
- Domain rules
- Historical incidents
- Organization-specific testing standards
Fine-tuning is the right tool when the system needs calibrated behavior:
- Coverage calibration
- Scenario prioritization
- Assertion quality
- Redundancy reduction
- Consistency across similar APIs
These are behavior-shaping problems, not retrieval problems. No amount of supplied context teaches a model which tests a QA engineer would keep. In KushoAI's system, retrieval still has a role: customer documentation and organization-specific standards can be retrieved and supplied as context. Fine-tuning sits alongside it, shaping the judgment that retrieval cannot provide.
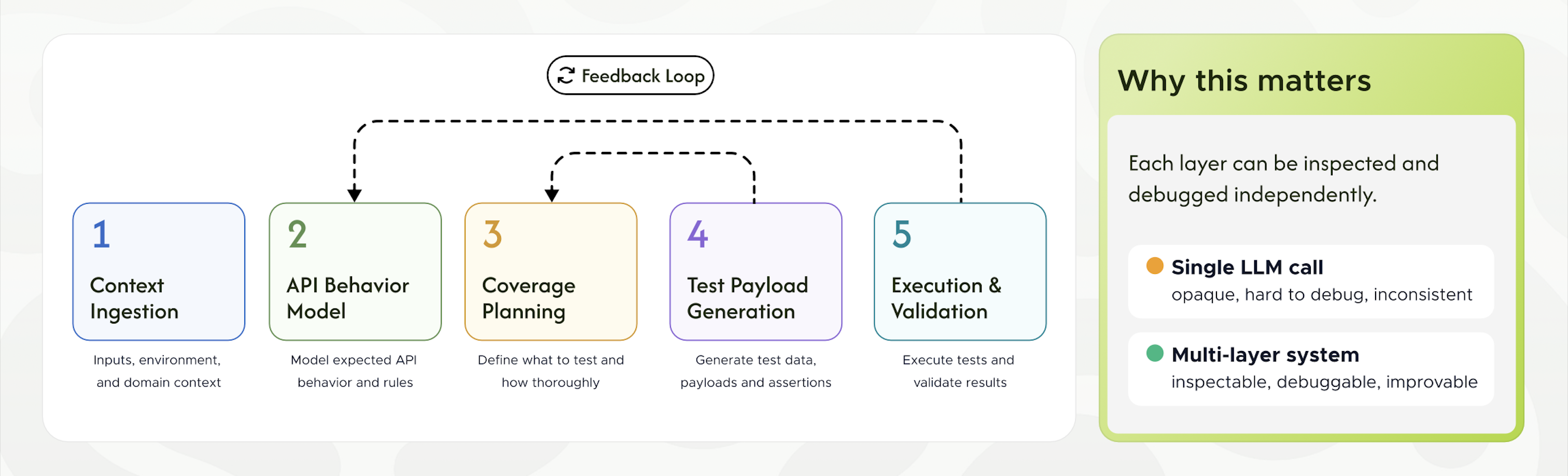
A Layered Architecture for AI-Native API Testing
KushoAI is a layered system rather than a single model call. Each layer has a defined input, a defined output, and can be inspected and improved on its own. The pipeline runs in seven stages.
- Context ingestion. API specifications, documentation, sample payloads, response schemas, observed responses, existing tests, authentication context, and workflow signals.
- Behavior modeling. Expected API behavior, schema constraints, authentication requirements, and relationships between fields.
- Coverage planning. Positive paths, negative paths, boundaries, field-level cases, cross-field cases, and workflow dependencies.
- Test and assertion intent. Fine-tuned judgment models define what should be tested and what should be asserted.
- Payload and code generation. Frontier models generate executable tests and framework-specific artifacts.
- Execution validation. Tests run against live APIs, responses are validated, failures are isolated, and reliability is scored.
- Feedback and maintenance. Accepted, rejected, edited, and failed tests feed back into correction workflows, and suites are updated as the system changes.
Because the layers are separate, a weakness in coverage planning can be diagnosed and improved without touching payload generation, and a model provider can be swapped in the generation layer without disturbing the judgment layer. The layers that differ most across systems are coverage planning and intent, where judgment lives, and the feedback loop, where corrections accumulate.
Separating QA Judgment from Execution Mechanics
Within the architecture, the most consequential decision is the boundary between judgment and mechanics.
Fine-tuned models decide the what: which scenarios should exist, which edge cases matter, what should be asserted, how much coverage is appropriate, and what to omit as redundant. Frontier models handle the how: constructing payloads, generating executable tests, writing code, and adapting output to a target framework. Building a valid request from a schema or emitting a framework-specific collection is something general-purpose models already do well. Deciding which cross-field states are worth probing on a payments endpoint is not.
Test intent model. Takes API metadata and a target field, operation, or group of fields, and outputs a structured list of scenarios in plain language. It is responsible for relevance, coverage breadth, redundancy reduction, field-level and cross-field scenario selection, and appropriate test volume. For a payments endpoint, it should not only test a missing amount or a wrong currency type. It should identify cases where amount, currency, payment method, refund status, and idempotency key interact to create invalid business states.
Assertion intent model. Takes the expected response schema and an observed response, and outputs validation statements in plain language. It runs after a response exists, which is what separates it from the test intent model. The difference between a weak assertion and a useful one is concrete. A weak assertion says the response should be valid. A useful set says the status should be 400, the error response should include a machine-readable error code, no transaction ID should be issued, and the rejected state should be reflected consistently in the response body.
Both models output intent, not executable code. Frontier models turn that intent into payloads and tests, which keeps the tuned surface small and easy to evaluate.

The Training Signal: Corrected QA Decisions
The valuable unit in the dataset is not a raw API example. It is a reviewed QA decision.
For each example, the pipeline generates tests or assertions, and a reviewer then removes redundant or low-value cases, adds missing scenarios, rewrites vague assertions, normalizes phrasing, and stores the corrected output as the training target paired with its input context. The correction signals include:
- An accepted generated test
- A rejected generated test
- A redundant test removed
- A missing edge case added
- A weak assertion rewritten
- A flaky test rejected after execution
- A cross-field case added by a reviewer
- A customer-edited test retained as signal
In governed deployments, feedback signals are incorporated according to the customer's data-control model. Corrections may remain tenant-local, customer-controlled, anonymized, or excluded from shared training workflows depending on deployment requirements. Secrets, credentials, and sensitive payload values are not used as training targets.
Each of these is an explicit judgment about coverage, prioritization, or assertion quality. The dataset is not just a collection of API examples. It is a collection of QA decisions. The platform has generated more than 7 million tests against live APIs, and the stream of real execution and real review is what keeps that collection growing and current.
If reviewers handle similar APIs differently, the model learns the inconsistency. Curation focuses on standardized phrasing, consistent granularity, duplicate and contradiction removal, formatting normalization, and consistent treatment of edge cases. The goal is a clean distribution of preferred decisions rather than the largest possible pile of examples.
Execution Feedback and Reliability Loops
Generated tests are useful only if they run and if their results can be trusted. Execution is the arbiter of usefulness, and it closes the loop back into the training signal.
Tests run against live APIs. Failures are expected, and they are isolated rather than discarded. The system identifies which part of a suite failed and repairs that part rather than regenerating everything. Reliability is scored from execution signals, so a suite that passes cleanly in one run and breaks in the next is visible as unstable rather than treated as correct. For high-risk changes, a human approval step can gate deployment.
The outcome of execution feeds back into corrections. Accepted tests, rejected tests, edited tests, and tests that proved flaky under execution all become signals that refine the judgment layer. This is what turns generated tests from a one-time output into a system that improves. The same execution that validates a suite today produces the corrections that improve generation tomorrow.
Evaluation: Measuring Usefulness, Not Just Validity
A generated test can be valid English and still find nothing. An assertion can be technically correct and still miss the behavior that matters. Evaluation therefore measures usefulness, not just validity.
The qualitative dimensions are coverage, precision against redundant or low-value tests, calibration of how much output is right for an API, stability across similar APIs and across reruns, assertion relevance, and human preference in blind comparison. Alongside these, execution-based metrics make quality measurable: bug detection against live implementations, execution success, run-to-run variance, false-positive rate, flaky-test rate, and the reviewer correction effort a suite requires. The most informative single method is blind reviewer comparison, where engineers judge outputs without knowing which system produced them.
Public benchmark anchor: APIEval-20. APIEval-20 is one public evaluation anchor for this work. It is intentionally narrow: each system receives a JSON schema and one valid sample payload, then generates tests that are executed against live APIs with planted functional bugs. The benchmark does not evaluate every dimension of API testing, but it isolates an important capability: whether generated tests can move beyond simple schema mutations and expose failures that depend on field relationships or operation semantics. That is where the separation between systems appears, and it lines up with the failure modes this paper started from. Full methodology and results are published separately.
Production and Deployment Considerations
Fine-tuning here is a continuous loop, not a one-time training event. In production it runs as a sequence: collect platform examples; generate outputs; review and correct; curate training data; fine-tune the narrow judgment models; evaluate against held-out examples and benchmark APIs; deploy only into the judgment layer; monitor output quality; and collect new corrections. Most of the improvement over time comes from better and more consistent corrections rather than from hyperparameter changes.
Keeping the tuned surface narrow has an operational benefit beyond quality. Because only the judgment layer is fine-tuned, the system is easier to test, easier to govern, and easier to adapt if model providers change.
Deployment patterns vary with an organization's data-control and governance requirements. The judgment layer can run on managed infrastructure or within customer-owned model environments, using managed fine-tuning paths today and open-weight models as that path matures. It can be deployed inside a customer VPC or on-premise for regulated or isolated environments, and it can use customer-approved models where governance requires it. Across these patterns, the considerations that matter are model governance, auditability, data isolation, and a human approval step for high-risk workflows. Outputs are standard test code that runs inside the customer's own pipelines, not proprietary artifacts.
Lessons Learned
- API test generation is a calibration problem before it is a code generation problem.
- Prompting helps, but examples are the signal that points toward fine-tuning.
- Fine-tuning works best for judgment, not general capability.
- Correction quality matters more than raw data volume.
- Human corrections are more valuable than generated output.
- Evaluation infrastructure is part of the product, not a step that precedes it.
- Judgment and execution should stay separate, so the training signal stays clean and each layer stays testable.
- Execution feedback turns generated tests into a learning system rather than a one-time output.
Future Direction: Workflow-Level Reasoning
Most real failures do not live inside one isolated endpoint. They appear across state transitions, permissions, create-read-update-delete sequences, payment and refund flows, user onboarding, and downstream side effects. The clearest direction for adaptive coverage is reasoning at that level.
Workflow-level reasoning. The system already generates workflow tests across related operations. The deeper work is reasoning about a workflow as a coherent flow, understanding how one operation's state constrains the next, rather than testing each endpoint in isolation.
Multi-step API reasoning. Closely related, this means modeling dependencies between create, read, update, delete, authentication, authorization, and state-transition operations so that generated tests reflect realistic usage sequences. Public benchmarking scopes these multi-step and stateful journeys out today, which marks them as the next capability to build and measure.
User feedback loops. Customer edits, accepted tests, rejected tests, and manually added assertions are becoming direct training signals, so the judgment layer reflects real-world preferences more closely over time.
Continuous retraining. As more APIs are processed and more corrections accumulate, the dataset refreshes and coverage consistency improves, as long as the review process stays disciplined.
Enterprise-specific judgment variants. Organizations with specific testing standards, regulatory requirements, or coverage priorities can have those preferences encoded directly into a tuned variant of the judgment layer.
Open-weight deployment. As open-weight models mature, fine-tuned open-weight variants become viable for customers that require private-cloud or on-premise control.
Conclusion
The future of AI-native testing is not only faster test creation. It is adaptive coverage: systems that understand product context, decide what deserves to be tested, validate generated tests through execution, and improve from corrections over time.
Fine-tuning is useful because it encodes judgment where judgment matters most, on the question of what to test and what to assert. But the durable architecture is the full loop: orchestration, correction data, judgment models, execution validation, evaluation, and maintenance feedback. The visible sign of getting that loop right is a test suite that finds the bugs that depend on how fields and operations interact, not only the ones a schema makes obvious.
About This Paper
This paper describes KushoAI's architecture for AI-native API test generation and adaptive coverage. It focuses on the role of model orchestration, fine-tuned QA judgment, internally generated correction data, execution validation, and feedback loops. Benchmark references are included as supporting evidence, with full methodology and results published separately.